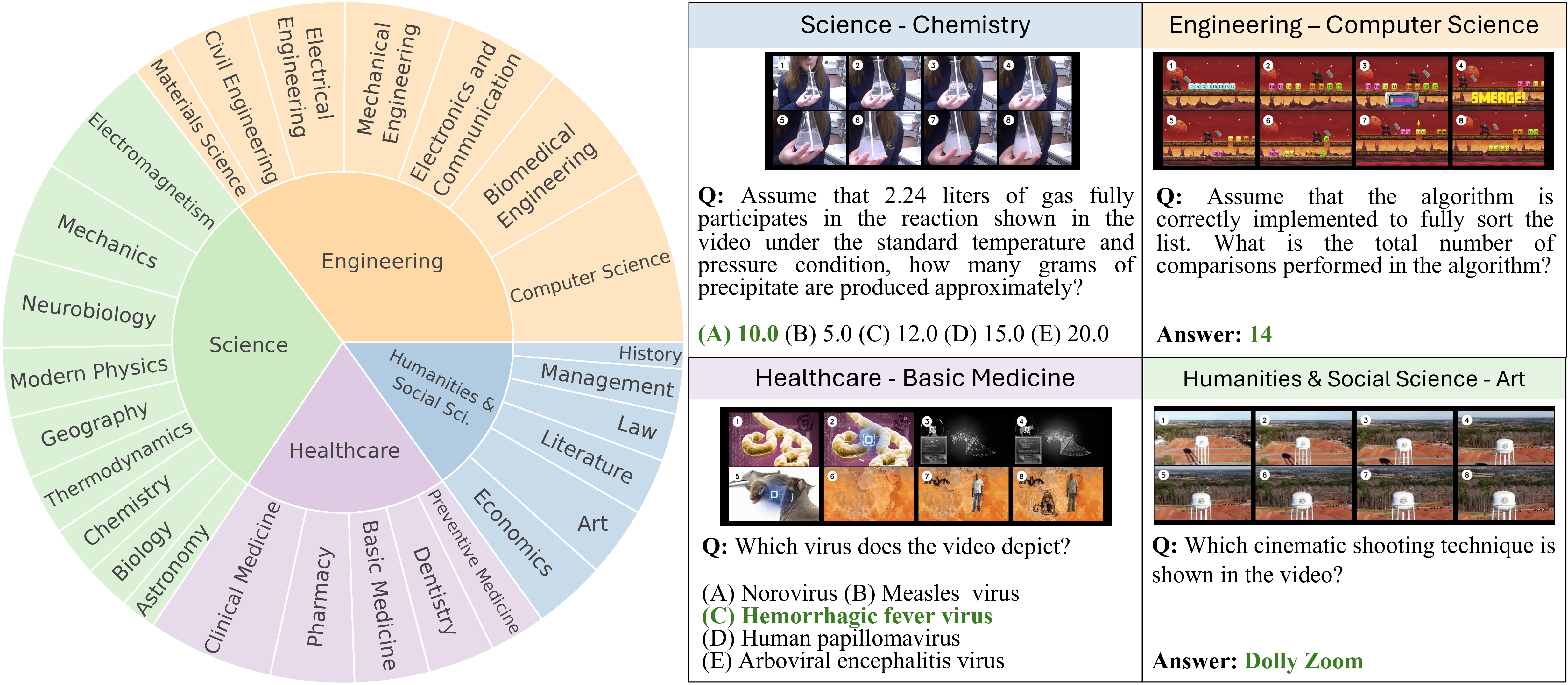
We introduce MMVU, a comprehensive expert-level, multi-discipline benchmark for evaluating foundation models in video understanding. MMVU includes 3,000 expert-annotated questions covering 27 subjects across four core disciplines: Science, Healthcare, Humanities & Social Sciences, and Engineering. Compared to prior benchmarks, MMVU features four key advancements: 1) Breadth of Domain Knowledge: We employ a textbook-guided QA annotation pipeline to ensure the wide coverage of domain knowledge within each subject; 2) Depth of Expert-level Reasoning: Each example requires models to comprehend specialized-domain video context, applying expert knowledge and reasoning; 3) True Visual Understanding: We confirm that video comprehension is required for accurate answering each example; 4) Support of Fine-grained Evaluation: We provide expert-annotated solutions and the requisite knowledge for each example, enabling more comprehensive analysis for future research. Through in-depth error analysis and case studies, we offer actionable insights to guide future advancements.
Accuracy of evaluated foundation models on the MMVU validation and test sets using CoT prompts. Model performance is ranked based on overall results on the test set.
| Model | MMVU (Val) | MMVU (Test) | ||
|---|---|---|---|---|
| Name | Date | # input frames | Overall | Overall |
@misc{zhao2025mmvu,
title={MMVU: Measuring Expert-Level Multi-Discipline Video Understanding},
author={Yilun Zhao and Lujing Xie and Haowei Zhang and Guo Gan and Yitao Long and Zhiyuan Hu and Tongyan Hu and Weiyuan Chen and Chuhan Li and Junyang Song and Zhijian Xu and Chengye Wang and Weifeng Pan and Ziyao Shangguan and Xiangru Tang and Zhenwen Liang and Yixin Liu and Chen Zhao and Arman Cohan},
year={2025},
eprint={2501.12380},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2501.12380},
}